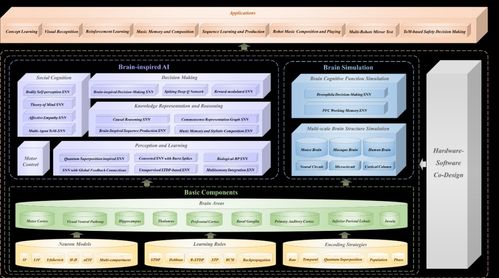
基于憶阻器的存算一體單芯片 清華高濱團隊展示1 POPS算力新突破
在2020年CCF GAIR(全球人工智能與機器人大會)上,清華大學高濱副教授團隊展示了一項前沿研究成果:基于憶阻器(Memristor)的存算一體(Computing-in-Memory)單芯片,其算力潛力可能高達1 POPS(Peta Operations Per Second,每秒千萬億次操作)。這一進展為突破傳統馮·諾依曼架構瓶頸、實現下一代高能效人工智能計算提供了極具前景的硬件路徑。
傳統計算架構中,數據需要在處理器和存儲器之間頻繁搬運,產生了巨大的能耗和延遲,即所謂的“內存墻”問題。這在處理人工智能,特別是深度學習的海量矩陣乘加運算時,成為提升算力和能效的主要制約。存算一體技術旨在將計算功能直接嵌入存儲器單元,在數據存儲的位置完成計算,從而極大減少數據搬運,實現能效的飛躍。
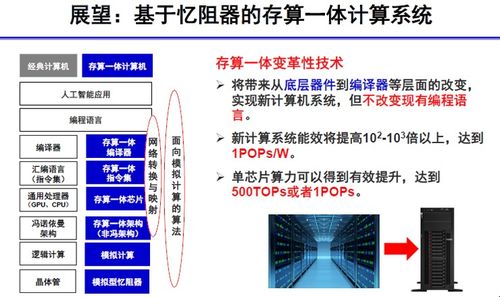
憶阻器作為一種新興的非易失性存儲器器件,其電阻值能夠隨流經的電荷量改變并保持,這一特性天然適合模擬突觸的權重,并直接在陣列中執行并行的模擬域乘累加運算。高濱團隊的研究正是利用憶阻器交叉陣列,構建了高效的存算一體硬件核心。他們所展示的芯片設計,通過高密度集成的憶阻器陣列和優化的外圍電路,能夠在單個芯片上實現理論峰值算力達1 POPS的驚人水平。這相當于每秒執行一千萬億次操作,為運行復雜神經網絡模型提供了強大的本地化算力支撐。
該技術的意義不僅在于超高的理論算力,更在于其革命性的能效提升。由于減少了大量數據移動能耗,存算一體芯片在執行AI推理任務時,能效比有望比現有GPU、TPU等傳統架構高出數個數量級。這對于在邊緣設備、物聯網終端等對功耗極其敏感的場景中部署復雜AI模型至關重要,有望推動人工智能在更多領域的普及和實時化應用。
在CCF GAIR 2020的報告中,高濱團隊也探討了與此類新型硬件相匹配的人工智能基礎軟件開發所面臨的挑戰與機遇。存算一體芯片,尤其是基于模擬計算的憶阻器芯片,其計算范式與數字處理器有根本不同,需要全新的軟件工具鏈、編程模型、算法以及神經網絡設計方法。這包括:
- 軟硬件協同設計:需要開發編譯器、映射工具,將神經網絡模型高效地映射到憶阻器交叉陣列的物理結構上,并管理其非理想特性(如器件波動、噪聲)。
- 算法與模型適配:設計適合存算一體模擬計算特性的神經網絡模型與訓練算法,以充分發揮其并行性和能效優勢,并克服模擬計算的精度限制。
- 系統集成與優化:探索存算一體核心與現有計算系統(如CPU、數字加速器)的異構集成方案,以及與之配套的數據管理、任務調度等系統級軟件。
高濱團隊的工作標志著我國在存算一體這一顛覆性計算技術領域已處于國際前沿。將高達1 POPS的潛在單芯片算力從理論推向大規模實用化,仍需在憶阻器器件的一致性、可靠性、大規模集成工藝,以及上文所述的完整軟件生態建設上持續攻關。這條道路無疑為應對后摩爾時代挑戰、滿足未來人工智能對算力與能效的無限渴求,點亮了一盞關鍵的引路明燈。
如若轉載,請注明出處:http://www.whwhm.com/product/61.html
更新時間:2026-02-19 01:52:55